In this Newsletter
- Introduction
- Structured and Unstructured Data
- Finding your Data
- Ways to Source the Data
Introduction
A key ingredient in your data story is arguably the data. However, where do you get your data? Do you need to pay for it, or can you get it for free? How do you source your data? Is it a manual download, or will you require some programming knowledge?
The questions can seem endless.
After you spend some time thinking through your topic, you'll need start looking for data to analyze. You may know exactly where you're going to source your data, which is awesome. However, you may also need to explore different sources of data to see which one is the best and most fitting to your data story.
Further, the reality is that managing the data within your data story can command specific skills. For example, you may require a programmer to write a web scraper or build a data ingestion script in Python. And then the data needs to be cleaned, transformed and normalized so you can adequately analyze the data. Thus, the data sourcing, ingestion and preparation phase can take time. But, after you get the data into a format and structure that can be analyzed, things tend to speed up. Also, like anything, the more you work with data, the more you'll know how to get through the hurdles.
So, let's start at the top and talk through two major types of data you'll come across: structured and unstructured data.
Structured and Unstructured Data
Structured data is information organized in a predefined format, making it easy to store, search, and analyze using traditional database management systems (DBMSs). If you've ever used a spreadsheet, then you're already familiar with structured data. Below is an example of a formatted spreadsheet.
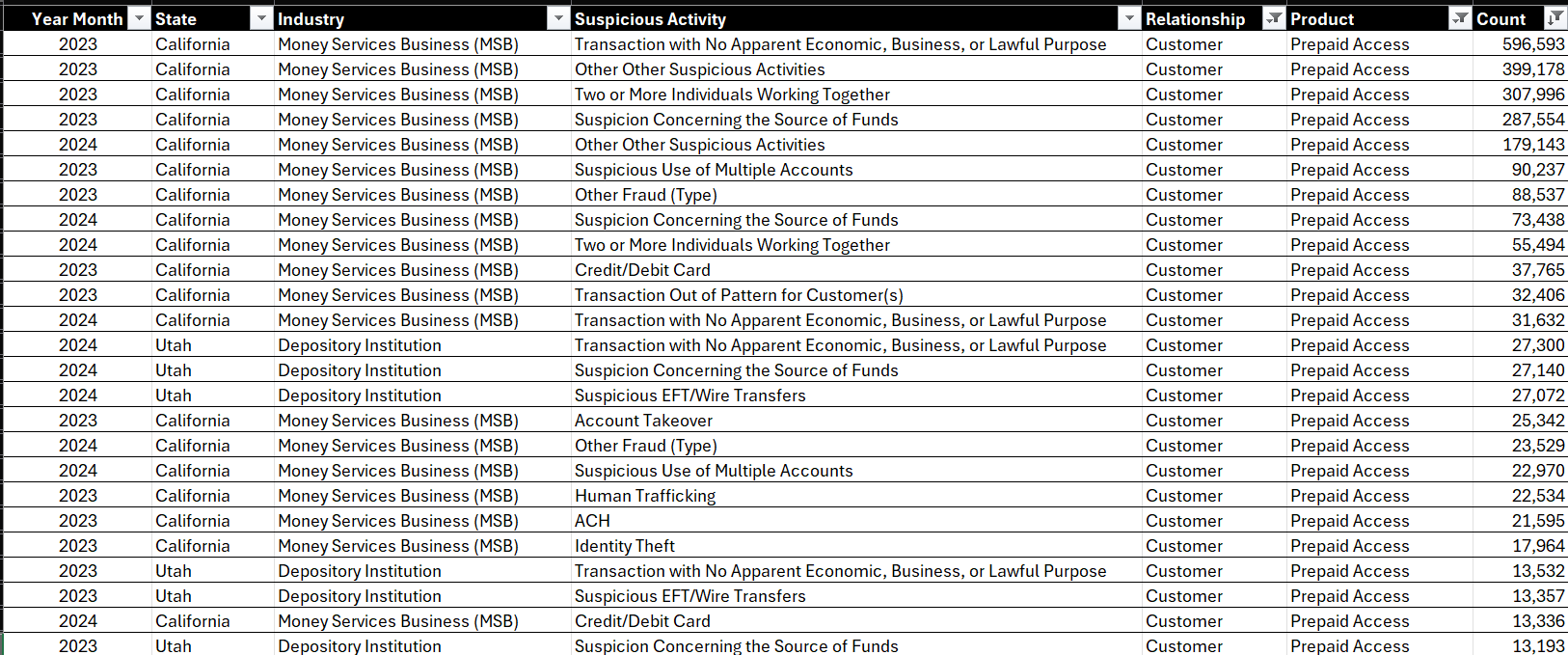
The key characteristics of structured data include:
- Format: Structured data is typically organized into rows and columns, similar to a spreadsheet or database table.
- Consistency: Data elements within structured datasets have consistent formats, data types, and relationships, making them suitable for relational databases.
- Accessibility: Structured data is easily accessible, manipulable, and queryable using standard SQL (Structured Query Language) or other database query languages.
Examples of structured data include:
- Databases: Customer databases, inventory databases, employee records, financial transactions, and sales reports stored in relational databases like MySQL, Oracle, or Microsoft SQL Server.
- Spreadsheets: Excel or Google spreadsheets containing tabular data such as budgets, schedules, product catalogs, or survey responses with predefined columns and data types.
- CSV Files: Comma-separated values (CSV) files used for data interchange, often containing structured data exported from databases or spreadsheet software.
Unstructured data, on the other hand, is information that lacks a predefined format or organization, making it more challenging to store, search, and analyze using traditional database systems. Social media posts or comments are examples of unstructured data.
The key characteristics of unstructured data include:
- Format: Unstructured data does not conform to a rigid schema or format, and it can include text, multimedia, and other content in varying structures.
- Variety: Unstructured data comes in diverse formats such as text documents, images, videos, audio files, social media posts, emails, PDFs, web pages, and more.
- Complexity: Unstructured data often contains complex and rich content, including natural language text, multimedia elements, metadata, and contextual information.
Examples of unstructured data include:
- Text Documents: Word documents, PDF files, emails, news articles, research papers, and social media posts containing textual information without a predefined structure.
- Multimedia: Images, videos, audio recordings, and graphics files that may contain rich content but lack a standardized format for analysis.
- Web Content: HTML pages, blogs, forums, and websites with diverse content types such as text, images, links, and interactive elements.
- Social Media Data: Tweets, Facebook posts, Instagram photos, YouTube comments, and other social media content generated by users in various formats.
Your analysis will be different across structured and unstructured data. For example, you might use quantitative analyses using tools like Power BI or Tableau when analyzing structured data. For unstructured data, you might use natural language processing techniques that are more attuned to qualitative data.
Finding your Data
When creating data stories, the data is key to your analysis and content creation. From investigative reports to data-driven stories, the ability to source, analyze, and present data is an important skill for journalists and content creators. Data sources can be broken down into primary and secondary data sources.
A primary data source refers to the original source of data that is collected firsthand by researchers, organizations, or individuals for a specific purpose or research project. In other words, primary data is data that is directly observed, measured, or collected from its original source without relying on pre-existing data or secondary sources. Primary data sources are often used in research, surveys, experiments, and studies to gather new information and insights.
A secondary data source refers to existing data that has been collected, processed, and published by other sources for purposes other than the current research or analysis. Unlike primary data, which is collected firsthand for a specific research project or purpose, secondary data is already available and accessible for use by researchers, analysts, and organizations. Secondary data sources can provide valuable information and insights, serving as a foundation for research, benchmarking, trend analysis, and comparison studies.
The following represent examples of primary data sources.
- Government Databases: Government agencies often provide a wealth of data on various topics, such as demographics, public health, crime statistics, and economic indicators. Websites like data.gov (for the United States) or Eurostat (for the European Union) are excellent starting points for accessing public datasets.
- Open Data Portals: Many organizations, including non-profits and research institutions, maintain open data portals where they share datasets related to their areas of focus. Examples include the World Bank's Open Data initiative and the Open Data Network.
- Surveys and Interviews: Conducting surveys and interviews can provide firsthand data from sources such as experts, stakeholders, or the general public. Tools like Google Forms, SurveyMonkey, and Zoom are commonly used for data collection in journalism.
- Freedom of Information Requests (FOIAs): In countries with Freedom of Information laws, journalists can submit FOIA requests to government agencies for access to specific documents or datasets that are not publicly available.
The following are examples of secondary data sources.
- Data Aggregators: Platforms like Kaggle, Data.world, and Statista aggregate datasets from various sources, making them easily accessible for analysis and visualization. These platforms often host competitions and challenges that can inspire story ideas. Note, in some cases there is a fee to access the data sources across these platforms.
- Social Media Monitoring Tools: Tools like Hootsuite, Brandwatch, and Mention can help track social media trends, sentiment analysis, and public reactions to events or topics. Social media platforms themselves, such as Twitter and Facebook, also provide APIs for accessing public data.
- Web Scraping: While it requires technical skills, web scraping can extract data from websites for analysis. Tools like BeautifulSoup (for Python) or import.io offer solutions for scraping structured data from web pages.
- Commercial Databases: Companies like Nielsen, Bloomberg, and Reuters offer access to proprietary datasets on topics such as market research, financial data, and industry trends. These databases often require subscriptions or licenses.
Regardless of whether you're sourcing primary or secondary data sources, you should try and follow some best practices for data sourcing.
- Verify Data Integrity: Always verify the credibility and accuracy of the data sources you use. Check for metadata, publication dates, and methodologies used in data collection.

- Cross-Reference Multiple Sources: Whenever possible, cross-reference data from multiple sources to validate findings and ensure a comprehensive understanding of the topic.
- Respect Data Privacy: Adhere to ethical standards and data privacy regulations when collecting, storing, and using data, especially if it involves personal or sensitive information.
- Document Your Sources: Keep detailed records of the data sources you use, including URLs, publication information, and any permissions or licenses required for use.
- Consider Bias and Context: Be aware of potential biases in data collection or interpretation. Consider the broader context and implications of the data you present in your story.
- Engage with Data Experts: Collaborate with data analysts, statisticians, or data scientists to gain insights into complex datasets and ensure accurate analysis.
Data sourcing is a foundational step in creating impactful data stories. By leveraging a combination of primary and secondary data sources, adhering to best practices, and utilizing data visualization techniques, journalists and content creators can unlock the power of data-driven storytelling. Stay curious, ethical, and innovative in your approach to data sourcing, and let the data guide your narrative.
Ways to Source the Data
There are various methods of sourcing data, each with its strengths and considerations. The method of sourcing data may also depend on the nature of your project. For simpler projects, manually downloading a dataset may suffice, whereas for more complex projects you may need to use a more advanced technique or even take a hybrid approach and combine multiple data sourcing techniques.
To follow are examples of different data sourcing techniques.
Public Datasets
Many governments, organizations, and research institutions make datasets publicly available for free or for a fee. These datasets cover a wide range of topics such as demographics, economics, health, education, and more. One example of an open government data source is data.gov, which you can see below includes thousands of searchable datasets.
Surveys and Interviews
Conducting surveys and interviews is a primary method of gathering qualitative and quantitative data directly from individuals or groups. Surveys can be conducted in-person, via phone, email, or online platforms like Google Forms or SurveyMonkey. Interviews can be structured, semi-structured, or unstructured depending on the research goals.
Web Scraping
Web scraping involves extracting data from websites automatically using software tools or programming scripts. It's useful for collecting data from multiple sources or tracking changes over time. However, ethical considerations and legal issues such as terms of service violations should be taken into account when scraping data.
Web scraping is typically done programmatically through, for example, Python and R. Examples of libraries that can be used for web scraping are Scrapy (Python) and Selenium (Web Automation Tool) and Beautiful Soup (Python). Here's a sample code snippet to illustrate web scraping using the Beautiful Soup library in Python. The code snippet below takes a fictional web site and uses the Beautiful Soup library to parse press release titles and links.
import requests
from bs4 import BeautifulSoup
url = 'https://www.example.gov/press-releases'
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
press_release_links = soup.find_all('a', class_='press-release-link')
for link in press_release_links:
title = link.text.strip()
href = link['href']
print(f'Title: {title}')
print(f'URL: {href}')
print('---')
else:
print('Error: Unable to retrieve data from the website.')
Social Media Monitoring
Social media platforms like Twitter, Facebook, LinkedIn, and Instagram provide APIs (Application Programming Interfaces) that allow developers to access public data such as posts, comments, likes, shares, and user profiles. As mentioned above, social media monitoring tools like Hootsuite, Brandwatch, and Mention automate the process of gathering and analyzing social media data.
Commercial Databases
Companies like Nielsen, Bloomberg, Reuters, and others offer access to proprietary datasets on topics such as market research, financial data, consumer behavior, and industry trends. These databases often require subscriptions or licenses for access.
Freedom of Information Requests (FOIAs)
In countries with Freedom of Information laws, journalists and researchers can submit FOIA requests to government agencies for access to specific documents or datasets that are not publicly available. FOIA requests may require justification and can take time to process.
APIs (Application Programming Interfaces)
Many websites and online platforms offer APIs that allow developers to access and retrieve data programmatically. This data can range from weather forecasts, stock prices, and news articles to public transportation schedules and geographic information.
Collaboration and Partnerships
Collaborating with other organizations, researchers, or data providers can provide access to specialized datasets, expertise, and resources. Partnerships can be formal (e.g., joint research projects) or informal (e.g., sharing data through networks or collaborations).
Purchase or Licensing
Some datasets are available for purchase or licensing from data vendors, market research firms, or data brokers. These datasets may offer unique insights or specialized data not available through public sources but come with costs and licensing agreements.
Each method of data sourcing has its advantages and challenges, and the choice of method depends on factors such as the research objectives, available resources, ethical considerations, legal constraints, and the type of data needed for analysis. It's important to select the most appropriate method(s) based on these considerations to ensure the quality, relevance, and integrity of the data for your data story.
Summary
In this newsletter, we introduced you to the practice of data sourcing. It's an important early step in the data story project, so understanding the different methods is important.
We also introduced you to the concepts of structured and unstructured data, the two types of data you'll likely be using. Structured data is organized in a predefined format, is easy to store, search, and analyze using DBMSs. Unstructured data lacks a predefined format or organization, making it more challenging to store, search, and analyze using traditional DBMSs.
We then walked you through primary and secondary data sources and discussed different approaches to sourcing your data – from manual downloads to programmatically accessing data through a Web API.
Subscribe today!

